ProFaNa - Instructions
Published : Sunday December 18 15:34:21

Welcome to the documentation for our ProFaNA! This tool is designed to help researchers analyse and interpret genomic context data. With this tool, you can efficiently perform neighborhood analysis using different input data (protein domain, gene set or protein sequence) This documentation will provide you with all the information you need to get started using the tool. It includes a detailed description of the tool's features and capabilities, as well as step-by-step instructions for using it to perform various types of analyses. We hope that this documentation will be a valuable resource for you as you explore the capabilities of our tool. If you have any questions or need further assistance, please don't hesitate to contact us. We are always here to help!

Here, we will present you an instructive example of neighborhood analysis using Pfam domain query on genera level. In the main menu view, click the button "Pfam domain as query (genera level)".
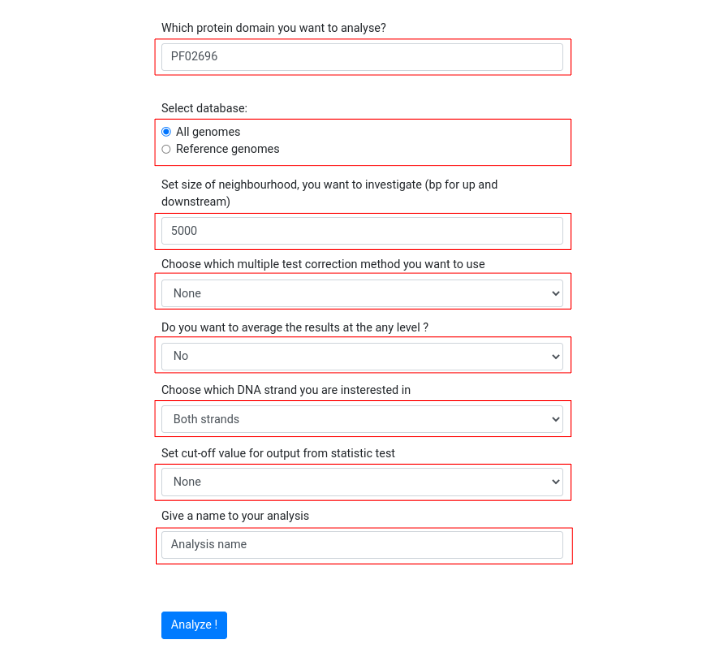
Then fill all fields with proper data. In this instructive example, we will analyze neighborhood for Pfam protein domain PF02696, size of neighborhood will be set to 5000 bp, we will use Bonferroni correction as multiple test correction method, genomes belonging to Escherichia genus will be searched for the query domain, both DNA strands will be investigated. From the results, we will discard domains which P score is higher than 0.00001. The analysis name will be set to "Example". Then, just press "Analyze!" button.

The analysis will be placed in a queue and will start as soon as possible. You will be redirected to the dashboard where all your analyses on this server will be stored. To view the status of your job, please click the button "Neighborhood analyzer".
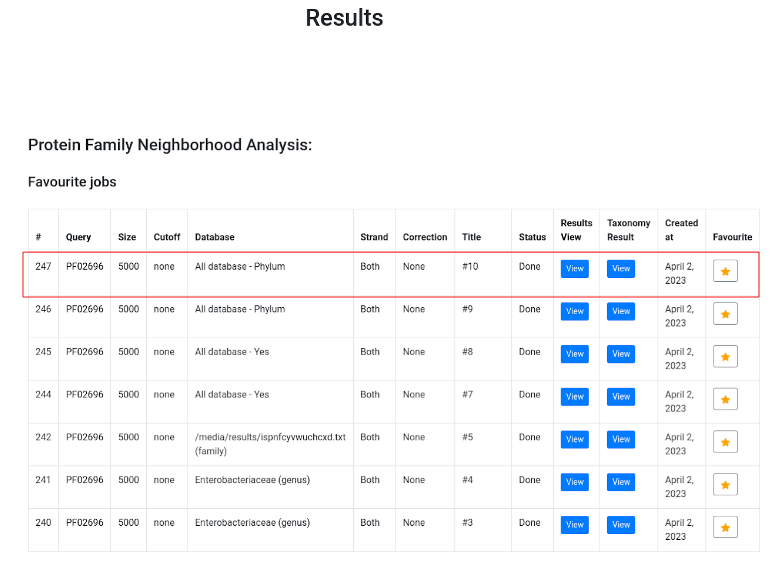
You can see the table with all jobs that you ever submitted. Here you can see that your job is in the queue. If everything is ok, placeholders "Please be patient" will be replaced with downloadable links.
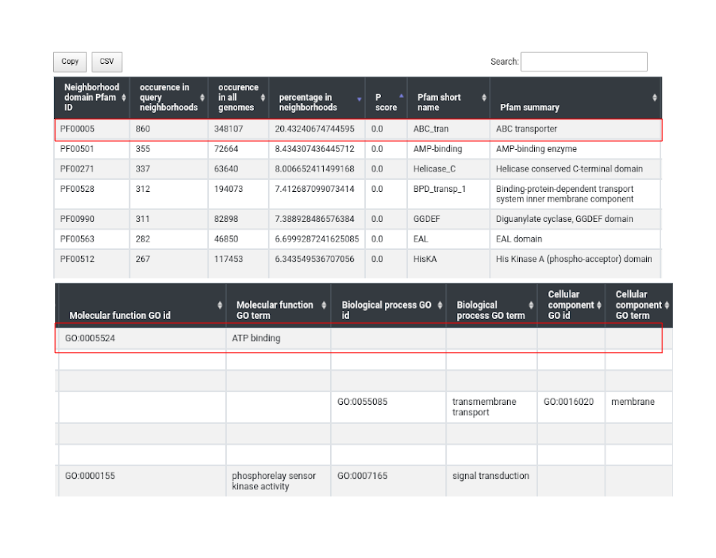
Results are presented in two files. In the first significant overrepresented domains with matching GeneOntology annotations are shown.
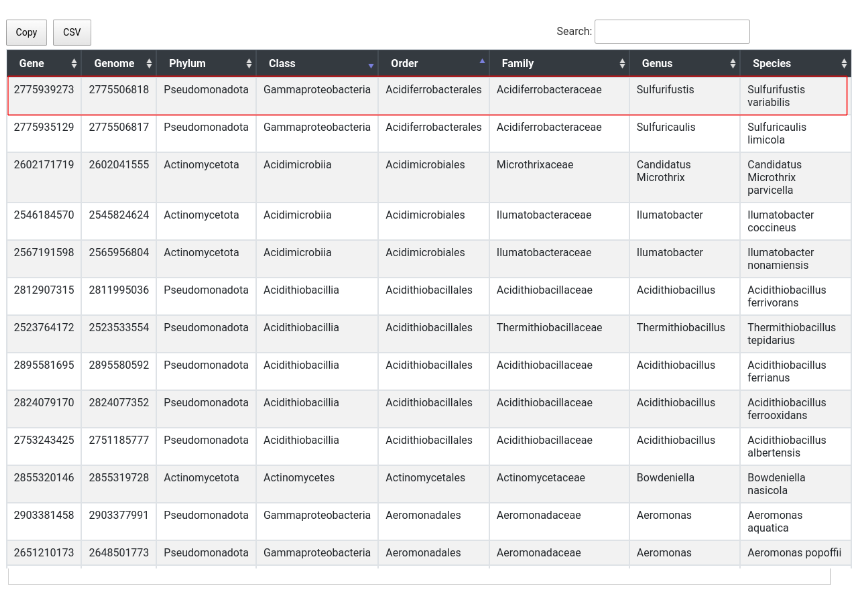
In the second file, taxonomy is presented as a table in which gene and organism query domain was found.
@uthor: @Bartek